In the ever-evolving landscape of web crawlers, PerplexityBot has emerged as a significant player. This AI-powered web crawler, used by Perplexity AI, indexes website content to provide search results for its chatbot. When users ask questions, PerplexityBot’s gathered information forms the basis of the AI’s responses, often including inline citations to source websites.
However, PerplexityBot’s behavior has sparked controversy. Despite claims of respecting robots.txt directives, it’s been accused of unethical scraping and bypassing access restrictions. Reports suggest it’s accessed restricted areas of websites using unpublished IP addresses, raising concerns among webmasters about data security and resource consumption. As a result, many site owners are now seeking effective ways to manage or block PerplexityBot’s access to their content.

What is Perplexity Bot?
PerplexityBot is the web crawler used by Perplexity AI to index website content for its AI-powered chatbot. This sophisticated crawler plays a crucial role in gathering information from various websites to provide search results and generate answers for user queries.
Overview of PerplexityBot
PerplexityBot operates as an AI search crawler, designed to navigate and analyze web content efficiently. Unlike traditional web crawlers, it doesn’t follow a fixed schedule for visiting websites. Instead, its crawling frequency varies based on factors such as user queries and content relevance. PerplexityBot’s flexibility extends to accessing specific pages on-demand, particularly when a user provides a direct URL to the Perplexity AI chatbot.
The bot’s user-agent identifies itself as “PerplexityBot” when accessing websites. It operates from a range of IP addresses, primarily associated with Amazon Web Services (AWS) infrastructure. This setup allows PerplexityBot to scale its operations and handle large volumes of web content efficiently.
Role in Indexing Content
PerplexityBot’s primary function is to index website content for Perplexity AI’s search capabilities. When a user asks a question through the Perplexity AI chatbot, the system utilizes the information gathered by PerplexityBot to generate an answer. This process typically includes inline citations to the source websites, providing users with references for the information presented.
The bot’s indexing process involves crawling web pages, extracting relevant information, and storing it in a format that can be quickly accessed and analyzed by Perplexity AI’s algorithms. This enables the chatbot to provide rapid, accurate responses to user queries across a wide range of topics.
PerplexityBot Complaints
Despite its innovative approach, PerplexityBot has faced criticism and complaints from website owners and publishers. The primary concerns revolve around the bot’s alleged disregard for robots.txt directives, which are meant to control crawler access to websites.
WIRED reported instances where PerplexityBot accessed restricted areas of its site and other Condé Nast properties that were explicitly blocked via robots.txt. These accusations suggest that the crawler may be bypassing standard access controls, raising ethical concerns about web scraping practices.
Perplexity initially dismissed these concerns, attributing the issue to a third-party crawling service. However, they later acknowledged that PerplexityBot might bypass robots.txt restrictions when a user provides a specific URL. This admission has led to ongoing investigations, including one by Amazon Web Services, to determine if Perplexity violated terms of service prohibiting such scraping practices.
How to Block PerplexityBot
Blocking PerplexityBot, the web crawler used by Perplexity AI, can be achieved through various methods. These techniques help website owners control access to their content and manage server resources effectively.
Blocking PerplexityBot via robots.txt
The robots.txt file is the primary method for blocking web crawlers. To block PerplexityBot:
- Access your website’s root directory
- Open or create a robots.txt file
- Add the following lines:
User-agent: PerplexityBot
Disallow: /This instructs PerplexityBot to avoid crawling any pages on your site. For partial blocking, replace the “/” with specific directories or files you want to restrict.
Remember, while robots.txt is generally respected, it’s not a foolproof security measure. Reports suggest PerplexityBot occasionally bypasses these directives, especially when users provide specific URLs.
Blocking PerplexityBot via .htaccess
For Apache servers, the .htaccess file offers another layer of protection:
- Locate or create the .htaccess file in your root directory
- Add these lines:
RewriteEngine On
RewriteCond %{HTTP_USER_AGENT} PerplexityBot [NC]
RewriteRule .* - [F,L]This code blocks any requests from user agents containing “PerplexityBot”. The [NC] flag makes it case-insensitive, while [F,L] returns a 403 Forbidden error.
You can also block specific IP ranges associated with PerplexityBot:
Deny from 54.176.188.0/25This blocks the entire AWS IP range used by PerplexityBot.
Blocking PerplexityBot via Cloudflare
Cloudflare provides additional options for blocking PerplexityBot:
- Log in to your Cloudflare dashboard
- Navigate to Firewall > Firewall Rules
- Create a new rule with these settings:
- Field: User Agent
- Operator: Contains
- Value: PerplexityBot
- Action: Block
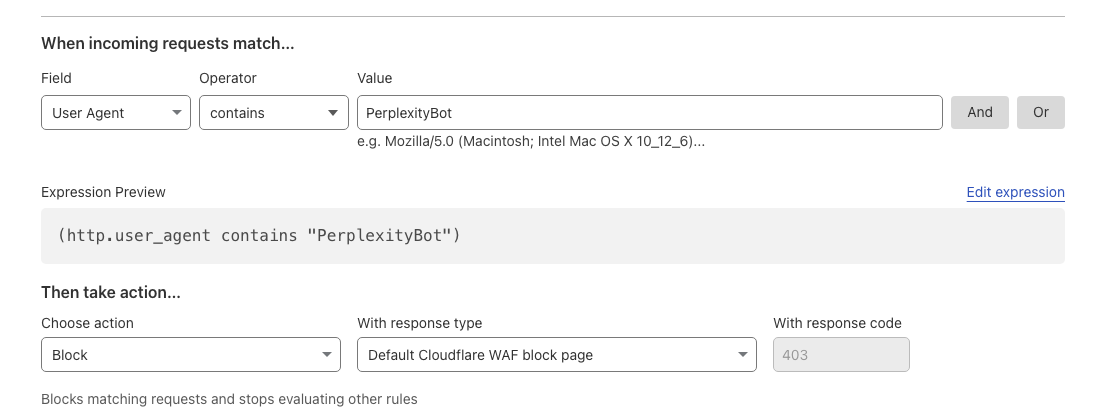
This rule prevents any requests with “PerplexityBot” in the user agent from accessing your site.
You can also create IP-based rules to block known PerplexityBot IP ranges:
- Go to Firewall > Tools
- Under “IP Access Rules”, add the IP range 54.176.188.0/25
- Set the action to “Block”
This method offers robust protection against PerplexityBot, even if it attempts to bypass robots.txt directives.
Should You Block PerplexityBot?
Deciding whether to block PerplexityBot depends on your website’s goals and priorities. Consider the following pros and cons to make an informed decision about allowing or blocking this AI-powered web crawler.
Pros of Allowing PerplexityBot
Allowing PerplexityBot to crawl your website offers several potential benefits:
- Increased visibility: Your content may appear in Perplexity AI’s search results, potentially driving more traffic to your site.
- Enhanced discoverability: Users asking questions on Perplexity AI might discover your content, even if they wouldn’t have found it through traditional search engines.
- Improved AI understanding: By allowing PerplexityBot access, you contribute to the AI’s knowledge base, potentially improving its ability to interpret and present information accurately.
- Potential for backlinks: If Perplexity AI cites your content as a source, it could lead to valuable backlinks and increased credibility.
- Stay competitive: With AI-powered search becoming more prevalent, allowing PerplexityBot access keeps your site relevant in this evolving landscape.
Cons of Allowing PerplexityBot
Despite the potential benefits, there are several drawbacks to consider:
- Resource consumption: PerplexityBot’s crawling can strain your server resources, potentially slowing down your website for human visitors.
- Content scraping concerns: There’s a risk of your content being used without proper attribution or in ways you didn’t intend.
- Loss of control: You have limited control over how your content is presented or used within Perplexity AI’s system.
- SEO competition: Perplexity AI might display your content in a way that reduces direct traffic to your site, potentially impacting your SEO efforts.
- Privacy and security: If PerplexityBot bypasses robots.txt directives, it might access sensitive areas of your website not intended for public viewing.
- Ethical considerations: Given the controversy surrounding PerplexityBot’s alleged disregard for robots.txt, allowing it might conflict with your ethical stance on web crawling practices.
When to Consider Blocking PerplexityBot
Deciding whether to block PerplexityBot depends on your website’s specific needs and priorities. If you value increased visibility and potential AI-driven traffic consider allowing it. However if you’re concerned about resource usage content scraping or privacy issues blocking may be the better choice. Evaluate the pros and cons carefully and align your decision with your site’s goals and ethical stance. Remember you can always adjust your approach later as your needs or the bot’s behavior evolves. Ultimately the choice is yours to make based on what’s best for your website and audience.